Comme je parle pas mal des choses cachées dans le son des CD et autres vinyles, je me suis rappelé un truc écrit dans un vieux magazine : des coordonnées géographiques d’hélicoptères cachées dans le son de vidéos YouTube.
Je ne suis absolument pas à l’origine de la découverte : c’est la blogueuse finlandaise Oona Räisänen qui a découvert ça en 2014.
Si vous vous demander ce que je raconte, je m’explique. Vous avez sûrement déjà vu les poursuites filmées en direct depuis un hélicoptère sur un BFM TV américain ? Les vidéos de ce type sont courantes sur YouTube et dans certains cas, on peut entendre une sorte de grésillement en arrière-plan. Ce grésillement est en fait la position de l’hélicoptère, transmise en direct. Si vous ne comprenez pas, la vidéo est assez éloquente, on entend bien le grésillement en question.
L’extraction de la position nécessite un peu de boulot. Il faut extraire une des deux voies, filtrer l’audio pour ne garder que les bonnes fréquences (entre 1 200 Hz et 2 200 Hz, par exemple avec Sox) et essayer d’interpréter le code . Le codage utilisé est le Bell 2020 (de l’ASCII en 7 bits) et il est donc possible de transformer la porteuse en texte lisible avec un programme comme Minimodem. Heureusement, la compression audio de YouTube n’a pas trop d’impact sur ce genre de choses.
Le texte récupéré, une fois passé dans une moulinette qui nettoie un peu, et en supprimant manuellement les quelques erreurs de décodages, donne des lignes de ce type : 39°06'90"N 94°44'65"W. Bingo, des coordonnées géographiques. Ensuite, il suffit de mettre ça dans un fichier standard et d’envoyer le tout vers Google Maps (par exemple).
Bon, c’est la version résumé que je vous fais, ça avait demandé un peu de réflexion. Mais du coup, à la fin, on peut obtenir ça. L’image que vous voyez montre les différentes positions de l’hélicoptère durant la vidéo.
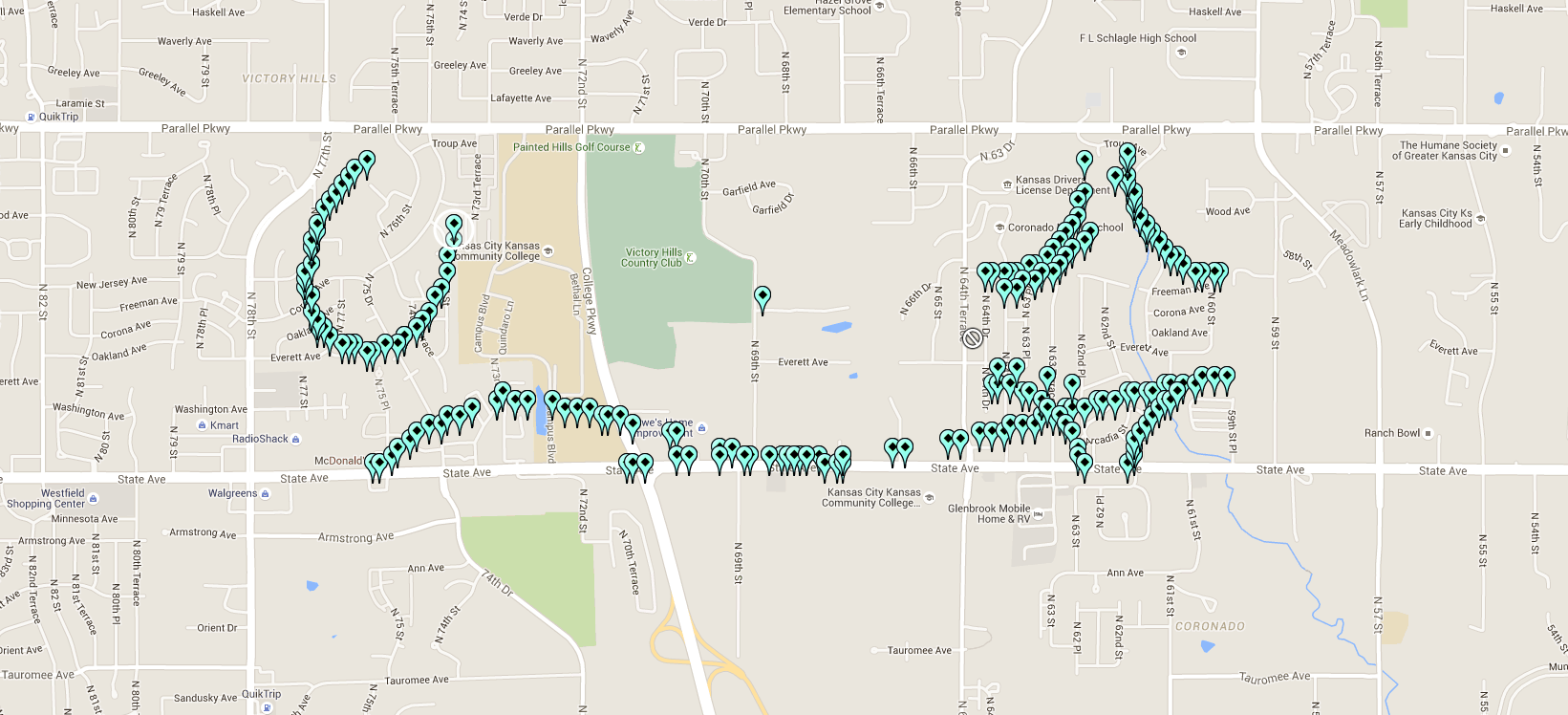
Les déplacements de l’hélicoptère
Je pense qu’il est possible d’obtenir un résultat valable en temps réel en utilisant un script, même si les erreurs inhérentes au décodage peuvent poser des soucis. Tout du moins, un script devrait permettre, au pire, de faire toutes les étapes automatiquement. Ce qui est finalement assez intéressant, ce n’est pas le décodage lui-même, mais le fait que des données a priori sensible peuvent se retrouver sur YouTube (ou sur le Net en général) via des canaux parfois étonnants.



Vraiment hyper interessant !
Tu aurais plus de précision pour la partie « Le texte récupéré, une fois passé dans une moulinette qui nettoie un peu, et en supprimant manuellement les quelques erreurs de décodages »
Comment tu arrives à définir ce qui est ou non à nettoyer etc ?
Juste pour la science, je m’essaierai bien à un petit script qui fait une partie du travail.
Et du coup, tu en a essayé plusieurs ?
C’était pour une page dans le mag’, donc non, j’en avais essayé qu’une, mais trouvé quelques autres. j’avais pris celle là parce qu’on entendait bien le truc, sans trop de gens qui parlent.
Pour le texte, j’avais juste utilisé minimodem, c’est dans leur doc. Le tri, je devais aller vite, donc en gros relecture rapide sur les caractères mal décodés en rechercher/remplacer. Ca se voit assez vite les erreurs, dans 99 % des cas, c’était juste un mauvais caractère dans une suite de chiffres. Ensuite, je me souviens avoir nettoyé aussi quelques positions mais de façon empirique, quand elle était vraiment complètement décalée. Mais sur un flux comme ça filtré, y a assez peu d’erreurs dans l’absolu.
Puis quelques expressions régulières pour le formatage pour obtenir du KLM. De mémoire, d’autres vidéos sur la même chaîne contiennent aussi les données.