Dans macOS Ventura, Apple a ajouté une fonction intéressante : un OCR dans les fonctions de numérisation. Si vous avez un scanner compatible avec macOS nativement (ou via un pilote moderne), il est possible de créer des PDF avec une zone de texte.
L’option OCR n’apparaît que si vous choisissez une sortie en PDF (c’est logique) et utilise Live Text, la reconnaissance de texte intégrée dans l’OS et – depuis macOS Ventura – dans les API dédiées aux PDF. Sauf qu’avec Transfert d’images, chez moi, ça ne marche pas.
Avec Transfert d’images, j’ai bien la case OCR (et encore, pas à chaque fois) mais le fichier PDF en sortie est dans tous les cas une image et pas un fichier avec des zones de texte. Ce n’est pas forcément visible pour une raison un peu bête : si vous ouvrez un fichier PDF avec Aperçu, il va utiliser Live Text et permettre de faire une recherche, copier le texte, etc.
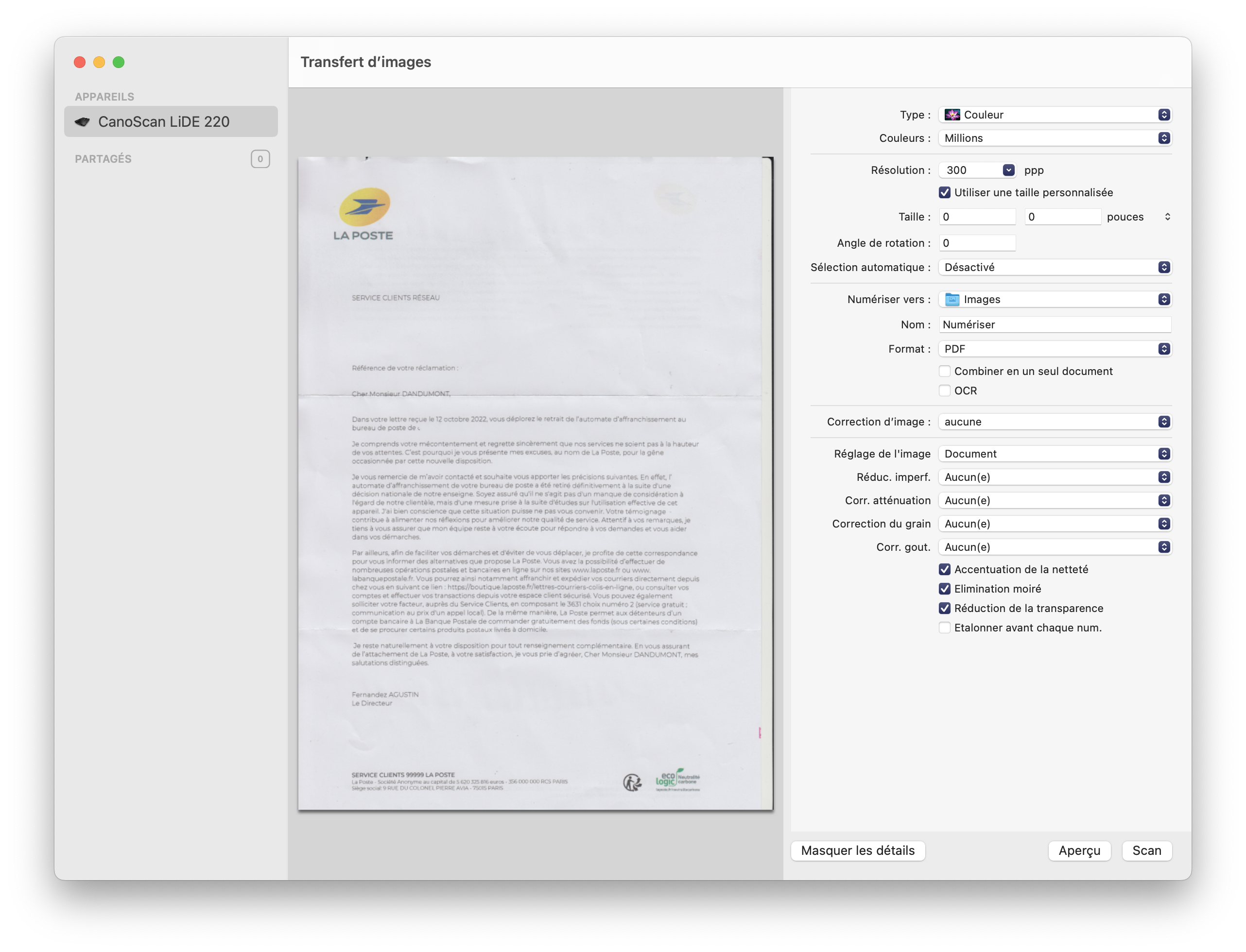
L’option sur le côté
Pour que ça marche, j’ai du passer par Aperçu, en réalité : Fichier -> Importer depuis nom du scanner. Puis bien cocher la sortie en PDF avec OCR (il faut parfois cliquer sur le format pour afficher la case). Après la numérisation, il faut bien cocher la case Intégrer le texte pour avoir des zones de texte. Et même comme ça, c’est franchement moyen dès que vous avez des zones séparées. Pour récupérer une page de texte continu, ça marche assez bien, par contre.
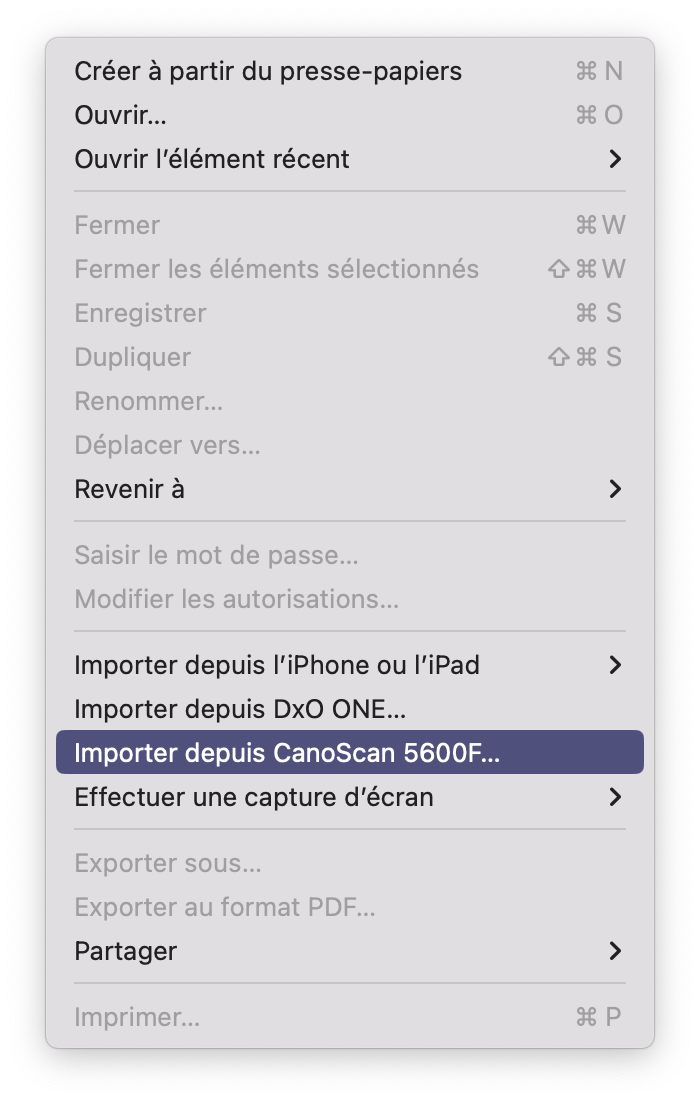
Importer
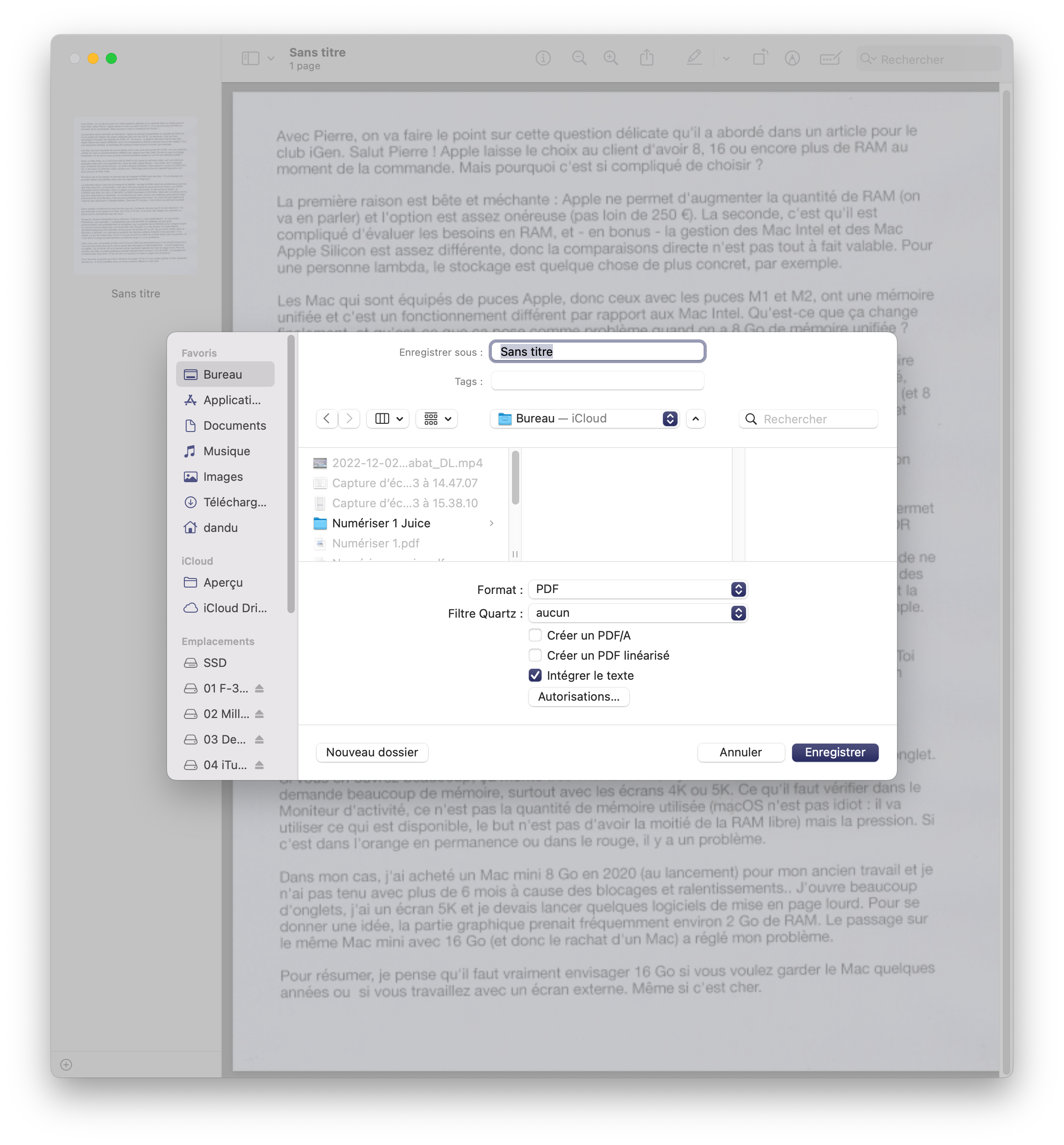
Sauver avec le texte
Je sais qu’installer un OS Apple avant sa version « .1 » est une mauvaise idée, mais ici, ça ne marche tout simplement pas. Par contre, c’est assez efficace pour la détection en direct et la recherche de textes, et c’est déjà pas mal.
Après, il y a peut-être une méthode précise où quelque chose que je ne comprend pas, mais je n’ai pas réussi à sauver un PDF avec une zone de texte.


